-End of Document-
Thanks for reading
Sometimes you want to know how long a script took and how much memory it consumed.
Run Time and Memory used can also be useful if tracked overtime, for example in:
While tools such as New Relic (paid), DataDog (paid), NetData (opensource), Prometheus (opensource) could be used, sometimes a simpler local solution is all that is needed.
Here is a simple Trait to extend your classes with
<?php
namespace App\Traits;
trait Stats
{
private $timer_start;
private $timer_finish;
public function statsTimerStart()
{
$this->timer_start = microtime(true);
}
public function statsTimerFinish()
{
$this->timer_finish = microtime(true);
}
public function statsTimerRuntime()
{
if (empty($this->timer_finish)) {
$this->statsTimerFinish();
}
}
Basic usage:
$this->statsTimerStart()
.. do stuff ..
log 'stuff processed in ' . $this->statsTimerRuntime() . ' using ' . $this->statsMemoryUsed();
Slim is a PHP micro framework that helps you quickly write simple yet powerful web applications and APIs.
https://www.slimframework.com/
Slim can also be used to run scripts or commands from the command line, also known as the cli.
While libraries such as symfony/console or even slim/console can be used, they can be rather cumbersome ie heavy when all you want to do is run a command and have access to your existing code and services in Slim.
The basic flow of a Slim API call could be envisioned as:
uri -> route -> action -> use query params
From the command line, there is no uri.
But maybe we could take the cli arguments and map that to a uri, and thus a route.
Perhaps such as
> php cli.php /cli/dostuff
Hmm, /cli/dostuff sure looks like a uri, right?
That can be mapped a Slim route nicely.
How about
> php cli.php /cli/dostuff?verbose=1&dryrun=1
Calling
<?php
if (PHP_SAPI != 'cli') {
exit("CLI only");
}
if (empty($argv) || count($argv) < 2) {
exit("Missing route for CLI");
}
// remove calling script
array_shift($argv);
// get route + params from 1st argument
$uri = array_shift($argv);
// group routes by /cli/
if (strpos($uri, '/cli/') !== 0) {
// handle os shell quirks
// windows git bash
if (strpos($uri, 'C:/Program Files/Git/cli/') === 0) {
$uri = str_replace('C:/Program Files/Git/cli/', '/cli/', $uri);
} else {
echo "uri: " . $uri . PHP_EOL;
exit("CLI Route must start with /cli/");
}
}
// get any more arguments
if (!empty($argv)) {
$additional = '';
foreach ($argv as $arg) {
if (strpos($arg, '=') !== false) {
// r=1 d=10
$additional .= '&' . $arg;
} else {
// normal args -r 10, store as argv
$additional .= '&argv[]=' . $arg;
}
}
if (strpos($uri, '?') === false) {
$uri .= '?';
}
$uri .= $additional;
}
// set uri based on cli arguments
$_SERVER['REQUEST_URI'] = $uri;
// normal Slim app, routes_cli_*, ActionCli
(require __DIR__ . '/cfg/bootstrap.php');
By putting a cleanup Lifecycle rule in place on your S3 buckets, you may be able to potentially save costs and increase LIST performance.
"Incomplete Multipart Uploads – S3’s multipart upload feature accelerates the uploading of large objects by allowing you to split them up into logical parts that can be uploaded in parallel. If you initiate a multipart upload but never finish it, the in-progress upload occupies some storage space and will incur storage charges. However, these uploads are not visible when you list the contents of a bucket and (until today’s release) had to be explicitly removed.
Expired Object Delete Markers – S3’s versioning feature allows you to preserve, retrieve, and restore every version of every object stored in a versioned bucket. When you delete a versioned object, a delete marker is created. If all previous versions of the object subsequently expire, an expired object delete marker is left. These markers do not incur storage charges. However, removing unneeded delete markers can improve the performance of S3’s LIST operation."
Source: https://aws.amazon.com/blogs/aws/s3-lifecycle-management-update-support-for-multipart-uploads-and-delete-markers/
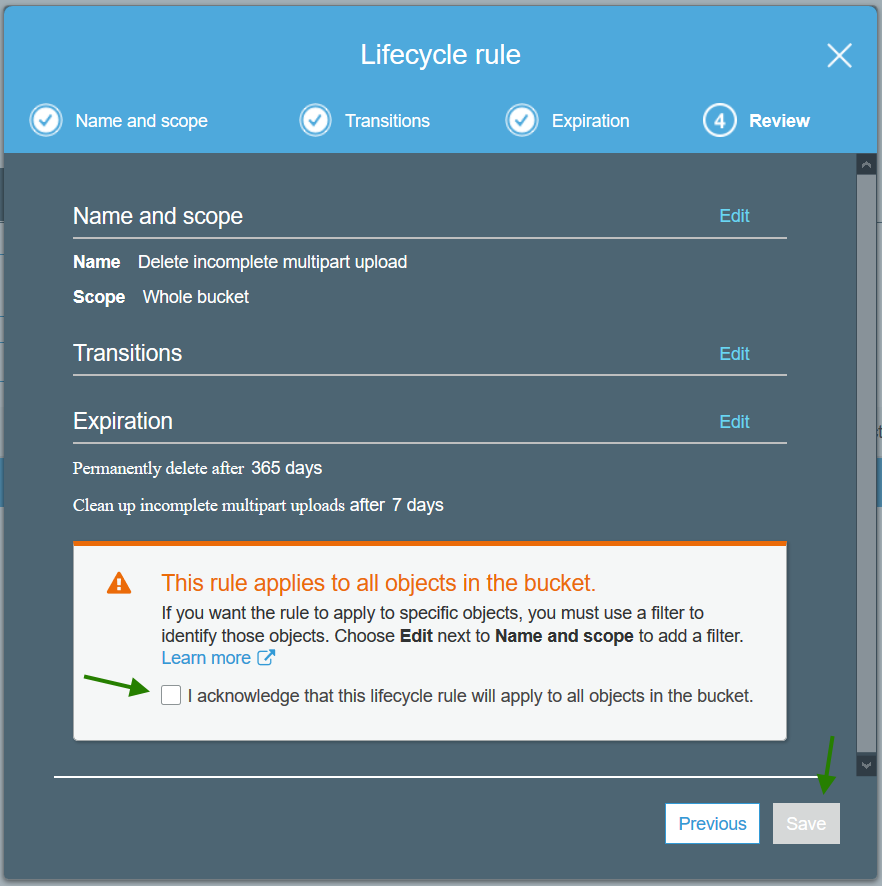
To add a cleanup Lifecycle rule:
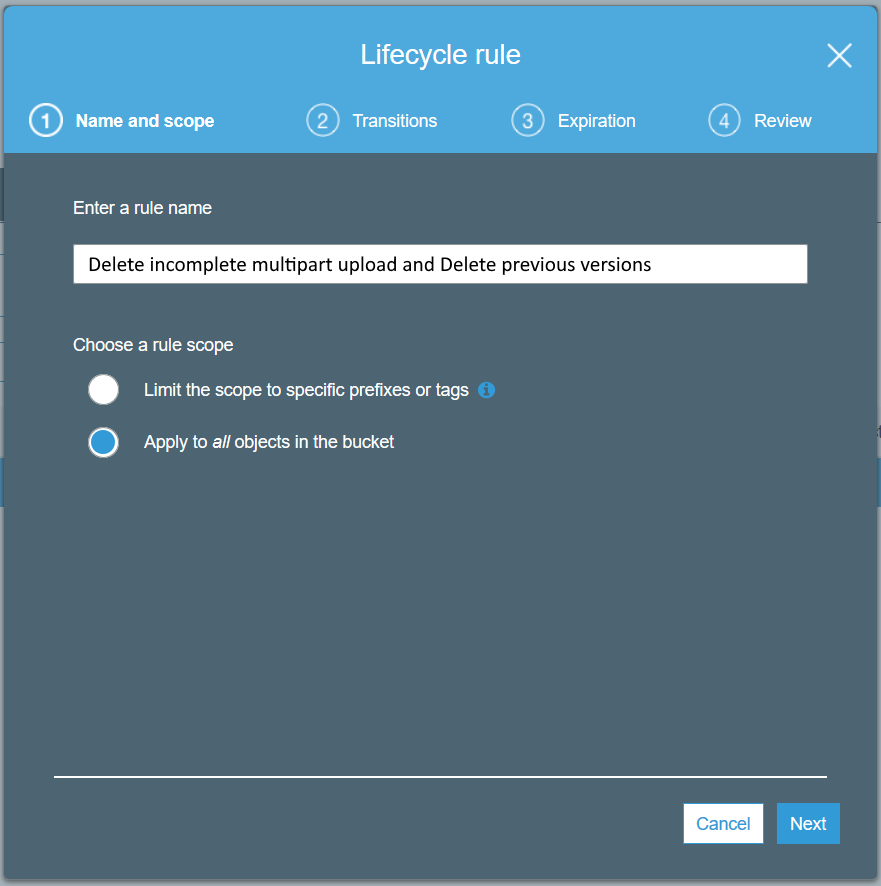
'Delete incomplete multipart upload and Delete previous versions'
Transitions allow you to move storage to slower locations at a reduced cost
https://docs.aws.amazon.com/AmazonS3/latest/dev/lifecycle-transition-general-considerations.html
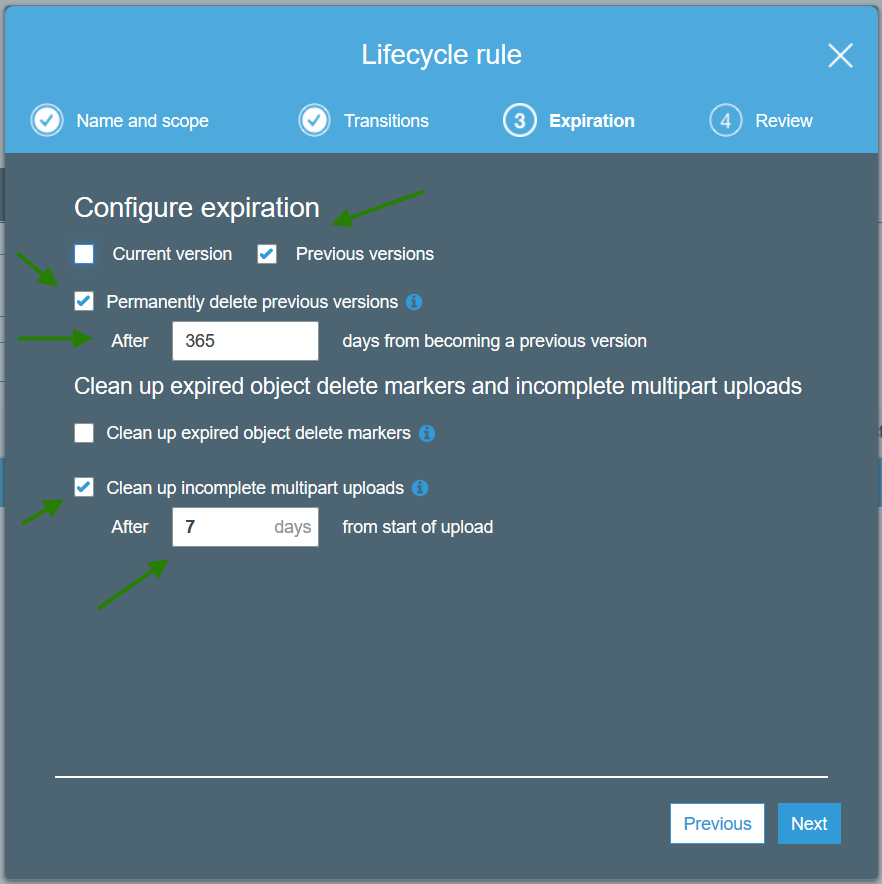
You can choose shorter periods such as 7 days or 30 days if you don’’t have a use case for retrieving prior S3 versions.
You will still have the current version, which is usually all you want, but deleting previous versions can help with costs and S3 LIST performance.
If you do not have any automated processes that may re-try uploads, you could choose 1 day
Agree to the 'scary' this applies to all objects in bucket
Note, if you have S3 objects (uploads) which require different policies, you may find it easier to manage by creating a S3 bucket per policy.
You now have some basic cleanup of your S3 bucket(s) configured.